MatterTune
An Integrated, User-Friendly Platform for Fine-Tuning Atomistic Foundation Models to Accelerate Materials Simulation and Discovery
*Corresponding author
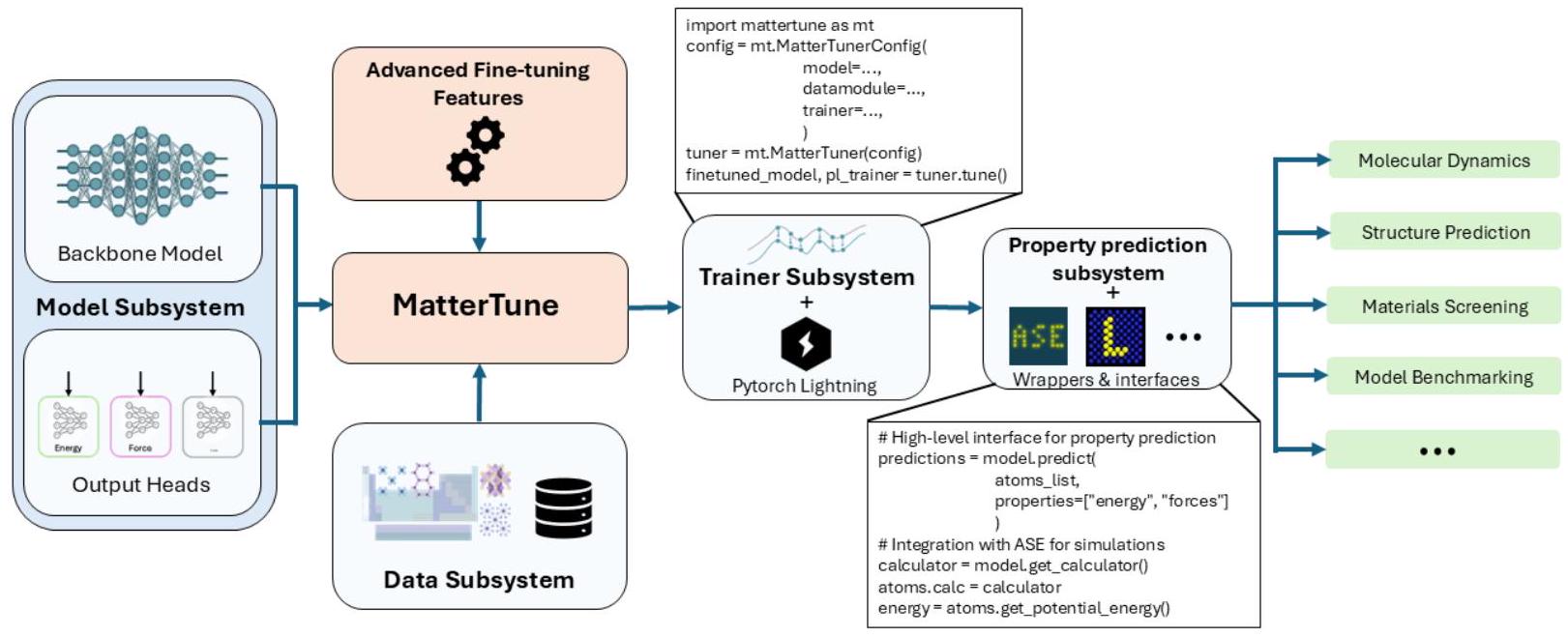
Figure 1: Overview of the MatterTune framework showing the modular architecture with data, model, trainer, and application subsystems.
Overview
Geometric machine learning models such as graph neural networks have achieved remarkable success in chemical and materials science research. However, their data-driven nature results in high data requirements, hindering application to data-sparse problems common in this domain.
MatterTune addresses this limitation by providing a modular and extensible framework for fine-tuning atomistic foundation models. These pre-trained models have learned general geometric relationships from large-scale atomistic datasets and can be efficiently adapted to smaller, application-specific datasets.
MatterTune supports state-of-the-art foundation models including JMP, EquiformerV2, MACE, MatterSim, ORB, and more, with features for distributed training, customizable fine-tuning strategies, and seamless integration with materials simulation workflows.
Key Features
Modular Design
Decouples models, data, algorithms, and applications for maximum flexibility and customizability.
Multi-Model Support
Unified interface for JMP, EquiformerV2, MACE, MatterSim, ORB, and more atomistic foundation models.
Parameter-Efficient Fine-tuning
Advanced fine-tuning techniques including EMA, learning rate scheduling, and composition-based normalization.
ASE Integration
Seamless integration with the Atomic Simulation Environment for molecular dynamics and structure optimization.
Distributed Training
Built on PyTorch Lightning for scalable, distributed training across multiple GPUs.
Few-shot Learning
Achieve high accuracy with as few as 30 training samples through effective transfer learning.
Supported Models
MatterTune provides unified interfaces for fine-tuning a growing collection of state-of-the-art atomistic foundation models.
JMP
Joint Multi-domain Pre-training
30M-235M params
EquiformerV2
Equivariant Transformer
31M-86M params
MACE
Higher-order Equivariant GNN
4.7M-9M params
MatterSim
Universal Atomistic Model
4.5M params
ORB
Scalable Neural Network Potential
25M params
M3GNet
Multi-fidelity GNN
~3M params
Nequip/Allegro
E(3)-equivariant Neural Networks
~1M params
UMA
Universal Materials Atomistic Model
~100M params
Citation
@article{kong2025mattertune,
title={Mattertune: An integrated, user-friendly platform for fine-tuning atomistic foundation models to accelerate materials simulation and discovery},
author={Kong, Lingyu and Shoghi, Nima and Hu, Guoxiang and Li, Pan and Fung, Victor},
journal={arXiv preprint arXiv:2504.10655},
year={2025}
}